
yuns
[IEEE20]Instance-aware Image Colorization 본문
Abstract
Image Colorization: 흑백의 이미지를 색이 있는 이미지로 변환시켜주는 기법
[이전의 Image Colorization 기법]
- 심층 신경망을 활용하여 입력 흑백의 이미지를 그럴듯한 색상을 입혀 직접 매핑
- 여러 개체를 포함하는 이미지의 경우에는 성능이 좋지 않음
- 원인: 기존 모델이 전체 이미지에 대한 학습 및 통합을 수행하기 때문에 명확한 경계 분리가 없을 경우에 학습이 잘 안됨
[Instance-aware Image Colorization]
- 객체 인식을 활용하여 잘린 객체 이미지를 얻고 instance colorization network를 사용하여 객체 수준의 기능을 추출
- 유사한 네트워크를 사용하여 전체 이미지 특징을 추출
- 융합 보듈을 전체 객체 수준 및 이미지 수준 특징에 적용하여 최종 색상 예측
* Image Segmentation은 네모 박스를 이용하여 bounary를 찾는 object detection와 달리 객체의 선에 따라 boundary를 찾는 기술이다.
Introduction
Image Colorization
- Multi-modal: 객체마다 여러가지 색을 가질 수 있는데 이 경우에는 그 중 하나를 선택해야 하기 때문
Key Idea
- 여러 객체의 boundary와 colorization의 성능을 개선
장점
- instance colorization을 학습하는 과정에서 background cluster의 생략으로 간단한 작업이다.
- localized object를 입력으로 사용하면 instance colorization network이 정확한 colorzation를 위하여 object 수준의 representation을 학습하고 background와 색상 혼동을 피할 수 있다.
과정
- off-the-shelf pre-trained model를 이용하여 object instance를 감지하고 object image를 생산
- off-the-shelf model
- 사전적 의미: 즉시 사용할 수 있고 특정 목적에 맞게 특별히 만들 필요가 없는 제품을 설명하는데 사용
- 바로 사용가능한 모델이라는 의미인듯
- off-the-shelf model
- 두 개의 네트워크(insance detection / colorization)의 end-to-end training
- 두 개의 네트워크의 layer에서 추출된 특징을 선택적으로 혼합하는 융합 모델.
Related Work
Scribble-based colorization
Example-based colorization
Learning-based colorization
Colorization for visual representation learning
Instance-aware image synthesis and manipulation
Overview

Input: grayscale image $X \in \mathbb{R}^{H\times W\times 1}$
Method
Object detection
detected object instance를 활용하여 image colorization을 향상시킴
object detector로 Mask R-CNN사용
bounding box $B_i$를 detect한 뒤, instance image인 $X_i$와 color instance image인 $Y_i^{GT}$를 잘라낸 뒤, $256\times 256$의 해상도의 크기로 image의 크기 변경
Image Colorization backbone
두 종류의 Image Colorization이 있음 - instance image colorization / full image colorization(기존의 연구에 사용된 image colorization을 사용함)
두 개의 네트워크는 같은 층의 레이어로 구성되어 있음
두 개의 네트워크로 각각을 예측할 수 있지만, 단순히 붙이기만 하면 픽셀의 불일칠초 인하여 visible visual artifacts를 생성하기 때문에 둘을 함께 합치는 방법이 필요하다.
Fusion module
앞에서 언급한 두 개의 네트워크를 합치는 작업에 대한 단계
j번째 layer에서 동작하는 Figure 4.
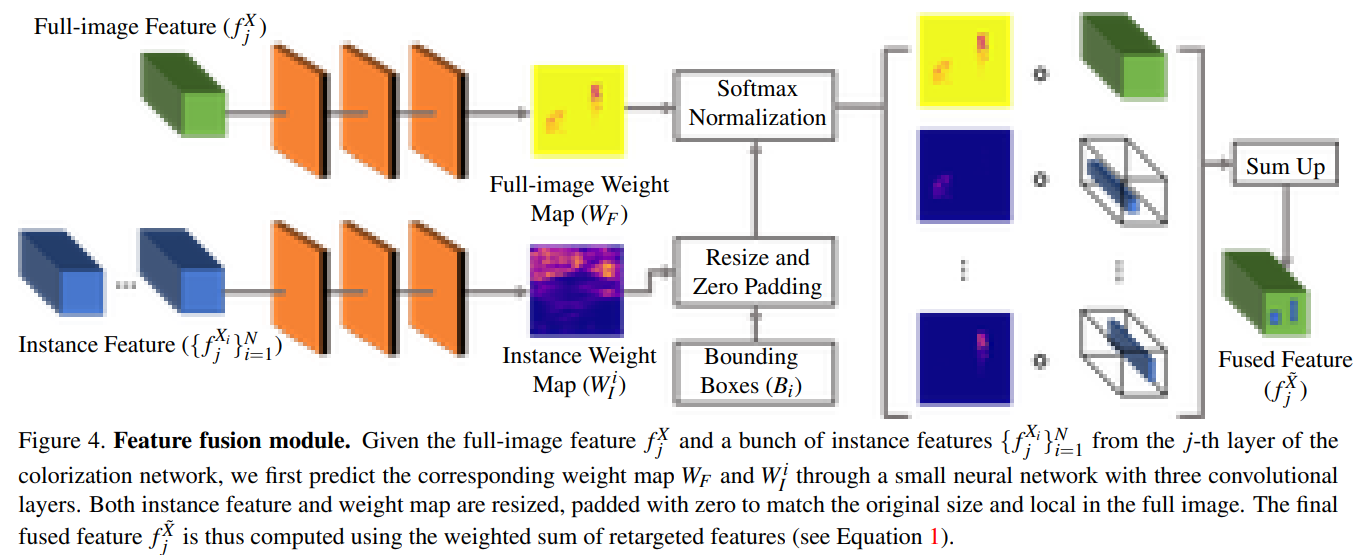
input
- a full-image feature $f_j ^X$
- a bunch of instance features and corresponding object bounding boxes $\{f_j ^{X_i} , B_i\}_{i=1}^N$
각 잘려진 이미지와 원본 이미지에 대하여 convolution layer를 통과 시킨 뒤, 잘려진 이미지에 대해서는 zero-padding을 한다. 즉, 잘려진 이미지를 제외한 부분을 0으로 값을 채우는 작업을 한다.
zero-padding을 진행 한 후에는 모든 feature를 합치는 과정을 진행한다.
Loss Function and Training
$$\mathcal{l}_\delta (x,y)=\frac{1}{2}(x-y)^2 1_{(|x-y|-\frac{1}{2}\delta)}1_{\{|x-y|>=\delta\}}$$
'화질 개선 프로젝트' 카테고리의 다른 글
| 관련 연구 (1) | 2021.05.03 |
|---|