
yuns
Attention Network 본문
반응형
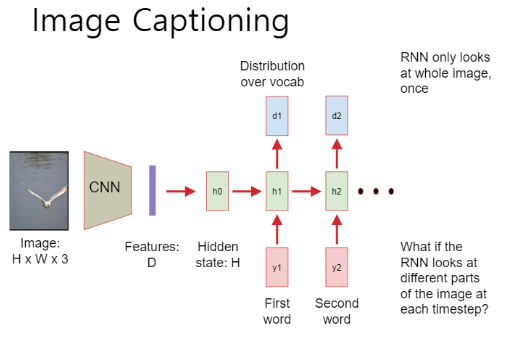
Image Captioning
- RNN의 하나의 타입으로 이미지 캡셔닝이 있음
- 이미지를 나타내는 캡션에 해당하는 문장의 다음 단어를 예측
- RNN을 이용하여 image captioning으로 다음 단어를 예측 한뒤 attention을 붙이는 방법?
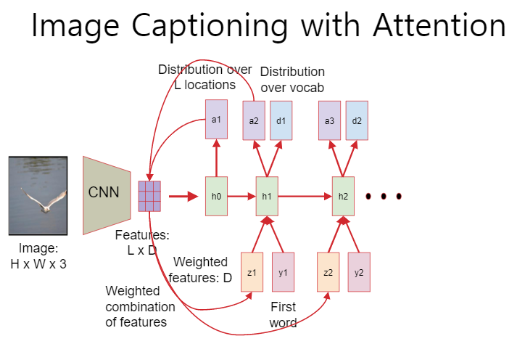
- feature가 L개로 나뉘어 있는 특징
- attention map
- hidden state map을 구성하는 방법
- 전체구간을 n개로 나누기 -> 각 잘려진 이미지에서 보기
- 각 잘려진 이미지에서 퍼센트를 다르게 보면서 값을 계산하기
- 학습된 feature와 얼마나 유사한지 정도에 따라 이미지 내의 캡션 예측
- 서로 다른 이미지에서 동일한 단어를 사용할 수 있음
- 선별적으로 뽑아내는 장치가 필요로 함
- 이미지 상에서 유사한 단어를 추출하고, 문맥상으로도 올바른지 체크함
- end token들어오면 종료
Visual Question Answering
- 질문과 이미지가 주어질 경우 질문에 해당하는 답을 이미지에서 찾아서 함
- 질문을 먼저 이해하기 예) Which is the brown bread? brown에 해당하는 이미지 조각에 attention을 많이 줌
Machine Translation
- 번역
- 입력 시퀀스의 마지막 시점의 벡터에 모든 정보를 다 담기가 버겁기 때문에 모든 입력 시퀀스의 정보를 조합하여 각 출력 단어를 생성
- Attention map
반응형
'goorm 수업 정리 > Deep Learning' 카테고리의 다른 글
| Generative Adversarial Network (0) | 2021.09.15 |
|---|---|
| Recurrent Neural Networks (0) | 2021.09.10 |
| Convolution Neural Network (0) | 2021.09.08 |
| Training the Neural Network (0) | 2021.09.07 |
'goorm 수업 정리/Deep Learning' Related Articles
more


Comments