
yuns
3. 머신러닝의 주요 알고리즘(4) - Support Vector Machine 본문
반응형
1. SVM이란?
서포트 벡터 머신(Support Vector Machine, SVM)은 지도 학습(Supervised Learning) 알고리즘 중 하나로, 분류(Classification)와 회귀(Regression) 문제를 해결하는 데 사용됩니다. 특히, 고차원 데이터에서도 효과적인 성능을 발휘하며, 작은 데이터셋에서도 강력한 일반화 성능을 보이는 것이 특징입니다.
2. SVM의 작동 원리
SVM의 핵심 아이디어는 마진(Margin) 을 최대화하는 최적의 초평면(Hyperplane)을 찾는 것입니다.
- 초평면(Hyperplane): 데이터 포인트를 두 개 이상의 클래스로 나누는 결정 경계
- 서포트 벡터(Support Vector): 초평면과 가장 가까운 데이터 포인트들로, 결정 경계를 형성하는 데 중요한 역할을 함
- 마진(Margin): 초평면과 서포트 벡터 사이의 거리로, 이 마진을 최대화하는 것이 SVM의 목표
3. 커널 기법(Kernel Trick)
SVM은 선형 분류뿐만 아니라, 비선형 데이터를 다룰 수도 있습니다. 이때, 커널 기법(Kernel Trick) 을 사용하여 저차원 데이터를 고차원 공간으로 변환할 수 있습니다.
대표적인 커널 함수는 다음과 같습니다:
- 선형 커널(Linear Kernel): 선형적으로 구분 가능한 경우 사용
- 다항식 커널(Polynomial Kernel): 다항식을 이용하여 비선형 데이터를 분류
- RBF 커널(Radial Basis Function Kernel, 가우시안 커널): 가장 널리 사용되며, 비선형 데이터를 효과적으로 변환
4. 파이썬을 이용한 SVM 구현
파이썬의 scikit-learn 라이브러리를 사용하여 간단한 SVM 모델을 구현해보겠습니다.
(1) 데이터 준비 및 시각화
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 데이터 로드 (Iris 데이터셋 사용)
iris = datasets.load_iris()
X = iris.data[:, :2] # 꽃받침 길이와 너비만 사용
y = iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 시각화
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', edgecolors='k')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Iris Dataset Visualization')
plt.show()
- target인 y에 따라 데이터 분포가 어떤지 matplotlib 로 확인
(2) SVM 모델 학습 및 평가
# SVM 모델 생성 및 학습
svm_model = SVC(kernel='linear') # 선형 커널 사용
svm_model.fit(X_train, y_train)
# 예측 및 정확도 평가
y_pred = svm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'SVM 모델 정확도: {accuracy:.2f}')결과: 0.90%로 정확도가 높은 편인 것을 확인할 수 있음
(3) 결정 경계 시각화
def plot_decision_boundary(model, X, y):
h = .02 # 격자 간격
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap='coolwarm')
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', edgecolors='k')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('SVM Decision Boundary')
plt.show()
plot_decision_boundary(svm_model, X, y)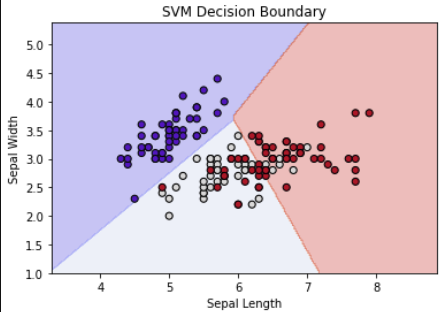
5. SVM의 장점과 단점
✅ 장점
- 고차원 데이터에서도 효과적
- 커널 기법을 통해 비선형 문제 해결 가능
- 작은 데이터셋에서도 우수한 성능 발휘
❌ 단점
- 대규모 데이터셋에서는 속도가 느릴 수 있음
- 하이퍼파라미터(C, 커널 종류) 튜닝이 필요함
- 이상치(Outlier)에 민감할 수 있음
요약
서포트 벡터 머신(SVM)은 강력한 지도 학습 알고리즘으로, 특히 분류 문제에서 뛰어난 성능을 발휘합니다. 선형 및 비선형 문제를 모두 해결할 수 있으며, 다양한 커널 기법을 적용하여 더욱 강력한 모델을 만들 수 있습니다.
실제 프로젝트에서는 SVM을 사용하기 전에 데이터 크기와 특성을 고려하여 적절한 커널과 하이퍼파라미터를 선택하는 것이 중요합니다. GridSearchCV를 활용하여 최적의 매개변수를 찾는 것도 좋은 방법입니다.
반응형
'머신러닝' 카테고리의 다른 글
| 4. 머신러닝 모델 개발 과정 - 데이터 수집 및 전처리 (0) | 2025.03.15 |
|---|---|
| 3. 머신러닝의 주요 알고리즘 - k-최근접 이웃(KNN) (0) | 2025.03.15 |
| 3. 머신러닝의 주요 알고리즘(3) - 랜덤 포레스트 (Random Forest) (0) | 2025.03.14 |
| 3. 머신러닝의 주요 알고리즘(2) - 의사결정나무 (Decision Tree) (0) | 2025.03.13 |
| Hugging Face Transformers 라이브러리의 Auto 클래스 (0) | 2025.03.13 |
'머신러닝' Related Articles
more
